Abstract
Recently, large language model (LLM)-based agents have made significant advances across various fields. One of the most popular research areas involves applying these agents to video games. Traditionally, these methods have relied on game APIs to access in-game environmental and action data. However, this approach is limited by the availability of APIs and does not reflect how humans play games. With the advent of vision language models (VLMs), agents now have enhanced visual understanding capabilities, enabling them to interact with games using only visual inputs. Despite these advances, current approaches still face challenges in action-oriented tasks, particularly in action role-playing games (ARPGs), where reinforcement learning methods are prevalent but suffer from poor generalization and require extensive training. To address these limitations, we select an ARPG, "Black Myth: Wukong", as a research platform to explore the capability boundaries of existing VLMs in scenarios requiring visual-only input and complex action output. We define 12 tasks within the game, with 75% focusing on combat, and incorporate several state-of-the-art VLMs into this benchmark. Additionally, we will release a human operation dataset containing recorded gameplay videos and operation logs, including mouse and keyboard actions. Moreover, we propose a novel VARP (Vision Action Role-Playing) agent framework, consisting of an action planning system and a visual trajectory system. Our framework demonstrates the ability to perform basic tasks and succeed in 90% of easy and medium-level combat scenarios. This research aims to provide new insights and directions for applying multimodal agents in complex action game environments. The code and datasets will be released.
VARP Agent Framework
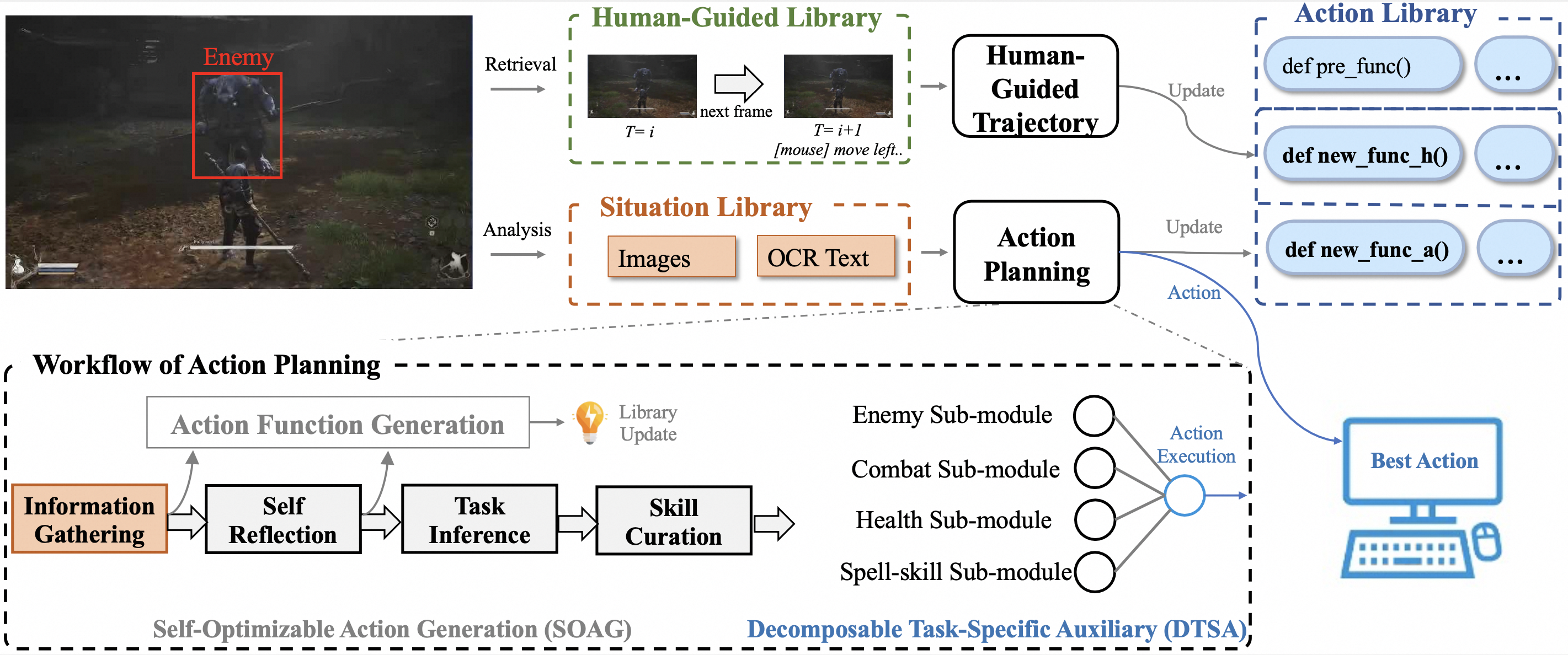
We propose a novel framework named the VARP agent, which directly takes game screenshots as input.
Through inference by a group of Vision-Language Models (VLMs), it ultimately generates actions in
the form of Python code, which can directly operate the game character. Each action is a sequence
that consists of various combinations of atomic commands. These atomic commands include light attack,
dodge, heavy attack, restore health, and others. Meanwhile, the VARP agent maintains three libraries:
a situation library, an action library, and a human-guided library. These libraries can be retrieved
and updated to store intensive knowledge for self-learning and human guidance. Overall, the VARP agent
is divided into two systems: the action planning system and the human-guided trajectory system.
In the action library, "def new_func_a()" represents the new action generated by the action planning
system, while "def new_func_h()" represents the action generated by the human-guided trajectory system.
"def pre_func()" represents the predefined actions.
Case Studies
Case studies of actions and corresponding game screenshots. The actions in the first and second rows are
predefined functions. The actions in the third row are generated by the human-guided trajectory system.
The new actions in the fourth and fifth rows are summarized by SOAG after each combat interaction between
the player character and the enemy and stored in the action library.